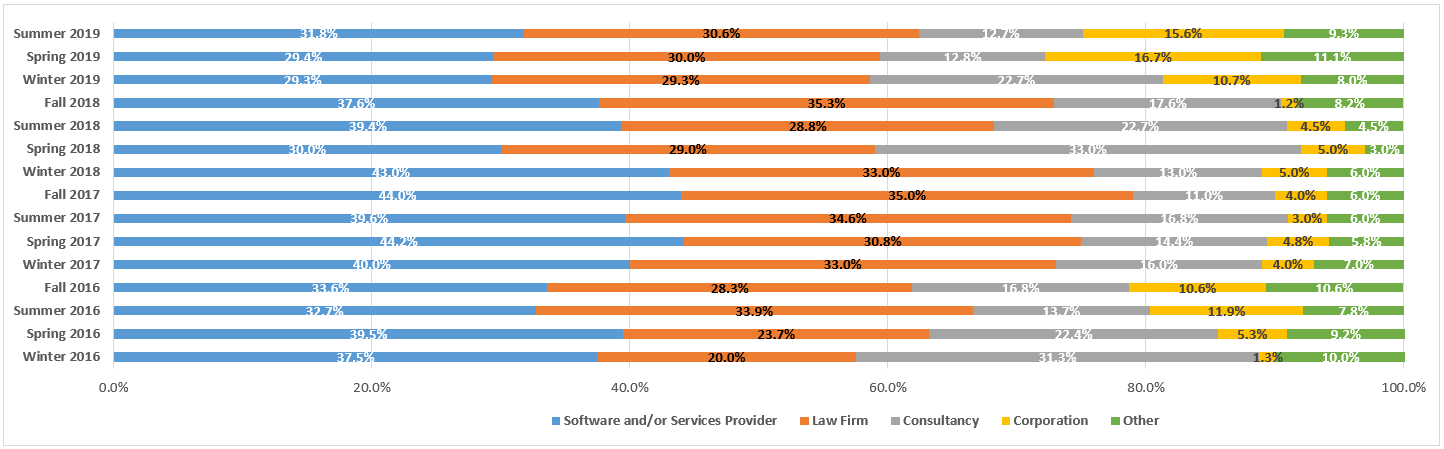
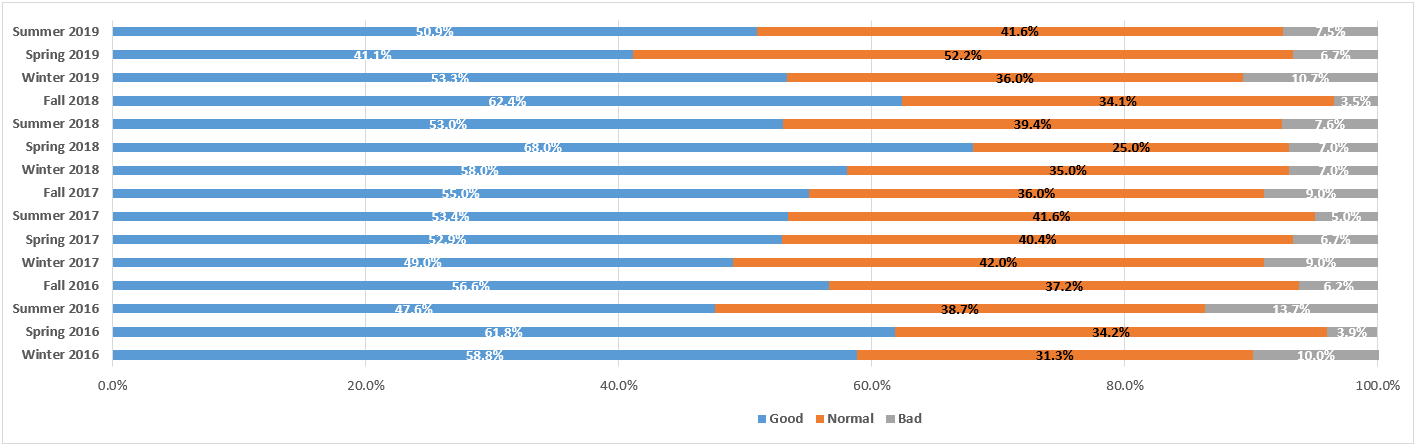
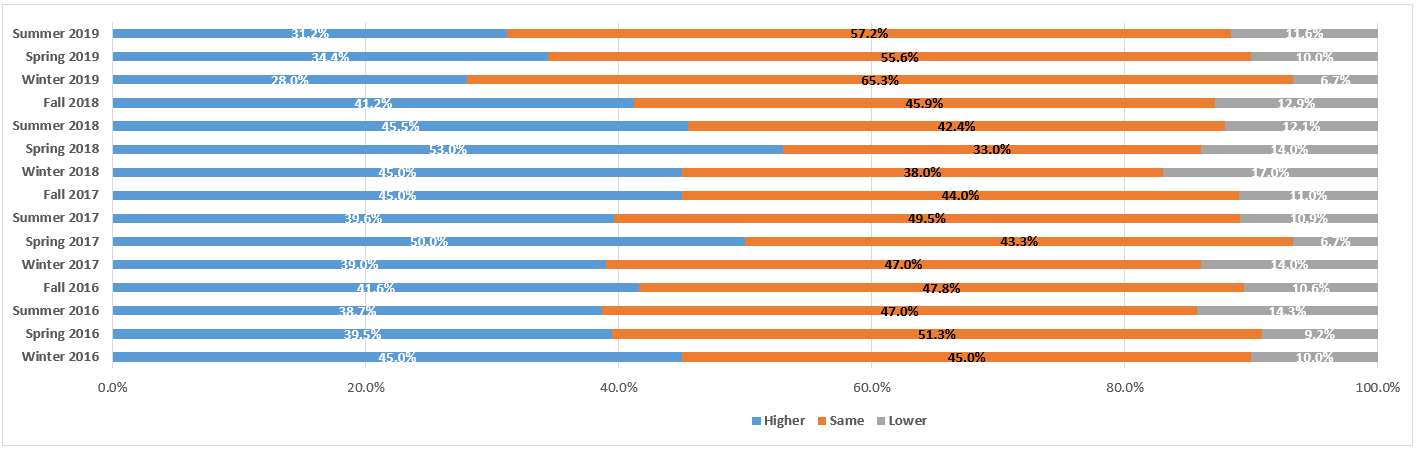
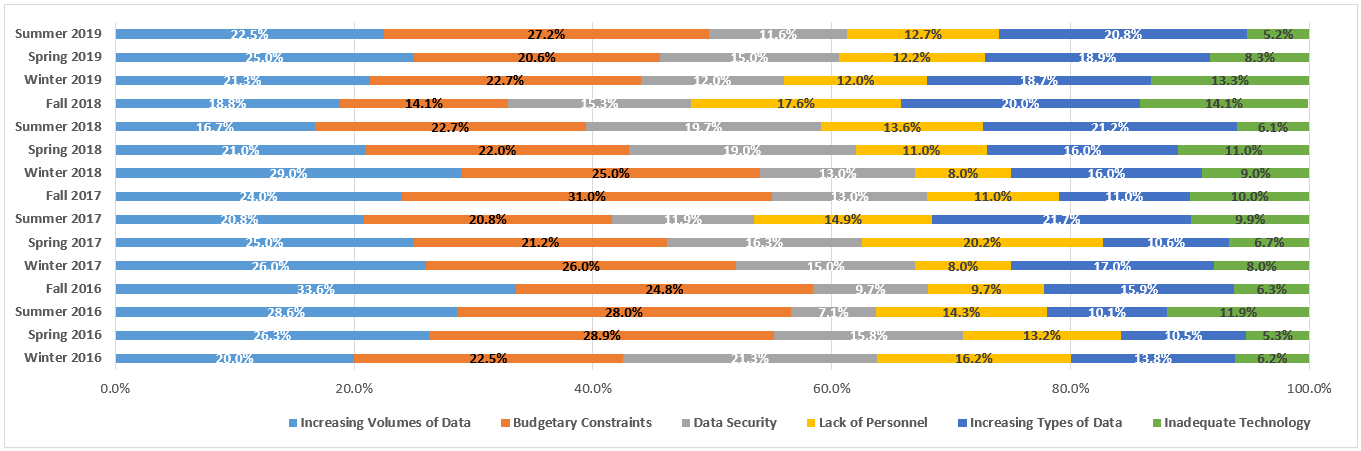
This is the seventh of the 2018 Legaltech New York (LTNY) Thought Leader Interview series. eDiscovery Daily interviewed several thought leaders at LTNY this year (and some afterward) to get their observations regarding trends at the show and generally within the eDiscovery industry.
Today’s thought leader is Jason R. Baron. Jason is a member of Drinker Biddle & Reath LLP’s Information Governance and eDiscovery practice and co-chair of the Information Governance Initiative. An internationally recognized speaker and author on the preservation of electronic documents, Jason previously served as the first Director of Litigation for the U.S. National Archives and Records Administration, and as trial lawyer and senior counsel at the Department of Justice. He also was a founding co-coordinator of the National Institute of Standards and Technology TREC Legal Track, a multi-year international information retrieval project devoted to evaluating search issues in a legal context. He served as lead editor of the recently published ABA book, Perspectives on Predictive Coding and Other Advanced Search Methods for the Legal Practitioner.
What were your general observations about LTNY this year?
{Interviewed the last day of the show}
We have come to a moment where artificial intelligence (AI) is being recognized as important for the legal industry. You see it everywhere. Five years ago, we saw the emergence of one form of AI in the guise of technology-assisted review in e-discovery. Now the moment has arrived for the merger of AI and law more generally — not just for the purpose of more efficiently finding relevant documents in the haystack, but using artificial intelligence techniques across a spectrum of legal contexts. That’s a good thing.
I just finished reading two books that I highly recommend to your readers. One is by Max Tegmark, called Life 3.0. Another is by the former chess grandmaster of the world, Garry Kasparov, called Deep Thinking. Both books talk about the rise of AI in our lives. Tegmark has this wonderful illustration of the rising waters of AI, where it now engulfs chess and Go, and is lapping up against more creative intellectual activities including story writing and software development. Whether we’re talking about robots, intelligent agents, or software with predictive powers, we are seeing AI replace tasks carried out both in factories as well as by the professional class. I would think that over the course of the next five to ten years, we’re going to see at Legalweek a greater and greater focus on AI applications in the law and what that means, including issues surrounding law and ethics.
The “trolley car problem” – involving whether one should throw a switch to make sure that a hypothetical train doesn’t hit a group of children instead of a large gentleman — is now a real problem faced by the makers of driverless car software. With driverless cars and taxis, you’re going to see injuries in some cases. So, there’s the question of liability, i.e., whether the software developer or manufacturer are held to a standard of strict liability, and what kind of ethical considerations are involved. We’re seeing a world of future hypotheticals coming into being across a whole range of applications. I think that’s exciting.
In your session at Legaltech regarding Internet and Things, your panel discussed privacy and ethics. When it comes to mobile devices, Internet of Things devices, and so forth, it certainly seems to me that a lot of attorneys would prefer not to worry about data on those devices or go collect from them. What do you think is going to be necessary to change that mentality?
I don’t know whether the mentality really has to change, especially in light of the 2015 Amendments that highlight the need for proportionality and discovery. I have always been a fan of iterative processes and tiered eDiscovery, so that you get early on the good stuff (i.e., the “low hanging fruit”). So now, we’re talking about a whole set of devices that are streaming data and a lot of applications that are out there – and what we discussed in that session and what I believe is that courts should be taking a hard look at the need for, in the first instance, going after all of these various types of communications and streams of data. In other words, a judge should be saying: “Why don’t we start with traditional email or text messages, and go on from there in terms of discovery of other apps and other data streams.”
I think the jury is out as to whether data from the Internet of Things is itself going to be at the center of a huge amount of litigation in the near-term. There’s clearly some case law already on personal wearable devices and there will be litigation about software used in driverless cars. And there are a bunch of cases in the civil and criminal areas where smart devices or intelligent agents (like Echo) seem to be omnipresent as evidence-gatherers – acting as an artificial “fly on the wall” when bad things happen in apartments or homes. So we are seeing at the margins some case law –but I’m not sure that there’s going to be a rapid rise in terms of eDiscovery case law with respect to all of these different appliances. I think the point though not to lose sight of is that we still have a large task in handling more traditional forms of documents and ESI, and that these may still be the “low hanging fruit” in many, many cases without worrying about exotic forms of IOT that may or may not be relevant. Nonetheless, we’re increasingly in a world of smart devices, so to the extent of smart devices provide evidence of something that’s going wrong in the world, and there’s a legal case to be had, that kind of data will have to be dealt with.
The bottom line is that competency for lawyers is changing. It’s not just whether you know the difference between various forms of technology assisted review and whether you’re up on the latest continuous active learning, TAR 3.0, 4.0, or whatever. It’s not just that. It’s not tied to the big case. It’s that you need to be aware that there are sources of data everywhere, in every case. Whether it’s a family law case or a personal injury case or whatever, there may be sources of data beyond what lawyers of a certain age know about in having previously sought. So, the duty of competence is really just basically the duty of keeping up with the world around us in 2018 and beyond.
Another big topic at the show has been GDPR. What are your observations on GDPR and how it’s going to impact, not just how information is handled in the EU, but how American companies are going to work with companies that have information in the EU?
The practice that I joined a few years ago at Drinker Biddle is an Information Governance and eDiscovery group. There’s a separate set of lawyers here who have been, for many years, experts in EU privacy law. It has been quite obvious to me in the last year in the run-up to GDPR that these practice groups really need to merge, and that the kind of questions that we are getting from companies with a global footprint about information governance are entwined increasingly with “what do we do about GDPR?” We will know more after May 25, 2018, of course, when compliance rulings and interpretations are handed down, and fines are levied, in terms of what constitutes best practices under the GDPR. But in the meantime, I’d say that GDPR-readiness is acting as a driver for US companies paying more attention to best practices in information governance. So I think it’s a good thing all of us have gotten a little bit up to speed on GDPR requirements.
I’ll tell you one aspect which may or may not be the sexiest topic in the world, but it’s the world I inhabit: on the issue of record retention, GDPR actually represents a sea-change in the way one goes about thinking about a corporate firm’s retention obligations. I’ve written about this in Ethical Boardroom and other places. The typical engagement for us as a law firm is being asked to provide advice on harmonizing a global set of record requirements into a schedule with simplified bigger buckets, coupled with automating processes around electronic content management.
It’s always been the perspective in US records schedules that the retention periods set out in the schedules operate as minimums for purposes of Sarbanes-Oxley, HIPAA, TARP, whatever. You name the vertical and it’s a minimum. For compliance purposes, you have to save data for a certain amount of years. If you save it longer, there’s no big penalty in most instances. Well, the GDPR is flipping that long-held assumption.
The specter of having an EU audit where your firm holds petabytes of data that involve potential personal information that has been in lying around for a decade or more after a retention period has ended is, shall we say, problematic. It’s not going to affect every company right away in May 2018. But, I would predict that if we’re talking in a year or two or three, some entity is going to be fined out there. Whatever the records schedule says now is a potential landmine for a company, unless it pays stricter attention to ensuring compliance with the retention periods within the schedule. The environment that I see is one which is probably good for lawyers, because at least at firms like mine, companies are coming to us saying they really haven’t grappled with the disposition of legacy data. They may have some policies in place, but it’s not really automated in a way that results in real deletion. The bottom line: what is needed are defensible deletion policies that are complied with in accordance with records schedules, so as to meet important aspects of the GDPR.
The last thing I’d say is that, as is well known, the entire subject of privacy represents a paradigm clash as between the US and the EU, especially with respect to the concept of the “right to be forgotten.” I actually have been on record for a number of years as being quite sympathetic to the EU perspective — for example, at Georgetown’s 2017 Advanced eDiscovery program I gave one of the so-called “eD talks (sort of like a TED talk), I said that I didn’t wish to be a shill for a future corporate Orwellian state. In that talk, I traced the issues that have animated me for the past 15 years or so about being smart in the eDiscovery space about search. But I also noted that AI has evolved to the point where we now are using analytics in ways that may be increasingly creepy in terms of surveillance of employees, or the ability to de-anonymize data on consumers.
All of that said, at Georgetown and in other talks I have lobbied for a notion of corporate responsibility in the AI and law space – arguing that there should be something akin to IRBs – human subject review panels – used, where corporations consider the algorithmic impact on people and a need for greater transparency on what decisions are being made by software. Beyond algorithmic bias and surveillance, I would bet there are a hundred other types of issues in the space that what I will call an “algorithmic review board” might be called upon to handle. But in my view there’s some level of corporate responsibility to be met in an increasingly AI era. So, I think the EU privacy model is one that we should pay attention to in terms of the impact of algorithms on our lives, and what it means to have some sort of zone of privacy that you have meaningfully consented to as an employee or consumer.
You mentioned blockchain and that another topic your panel discussed in your session yesterday. How do you see that unfolding and the impact of watching on the legal industry?
As I said at the session the other day, on the Gartner hype cycle the buzz around blockchains is definitely going up. Of course, regulation of cryptocurrencies is a very hot topic. However, blockchain and distributed ledger technologies are not just Bitcoin or ICO’s. Rather, blockchains represent a new way of establishing trust on the internet. One can imagine endless variations and possibilities of using blockchain applications for good purposes that have nothing to do with cryptocurrencies. You can use the distributor ledger technology for record keeping, for supply chains, for any number of applications which are of great interest. There isn’t a day that goes by where I don’t see some article that says ”Blockchains will be a disruptive force in ‘such and such’ industry.” Now, is it hype? Some of it may well be, but I think that, at bottom, the idea that you can hash information in a way to put together in a chain and make it immutable — where you have trust that that chain retains within it some kind of authentic pointers to information, and that you basically trust the objects themselves in a way that doesn’t rely on third parties — is exciting.
It’s a very interesting development. You see a lot of interest across industries. There’s still a certain mystery to blockchain. Where are mining operations? Who’s doing the mining? How do the algorithms work? What is a blockchain’s future when all the tokens have been mined? I myself have questions about all of that and don’t profess to understand all the details. But, I have been really interested in the potential for these applications and we’re going to see it talked about more and more. If AI was the primary new thing for Legalweek this year, I think blockchain was also right up there. We’ll see in the future.
I think there’s a wonderful moment here where more lawyers should be involved in at least knowing what the technology is all about and thinking creatively about its applications for the future.
What would you like our readers to know about things you’re working on?
My professional interests are a bit different from most of the people that hang out at Legaltech, mainly due to the fact that I spent 33 years in the government, including at the Justice Department and as Director of Litigation to the National Archives. I still have a passion for how to preserve and how to access public records in digital form. I’ve been very privileged over the last year to give talks in Amsterdam, in Vienna, in Cape Town, in London, and in the US and Canada all on the subject of how we should be thinking about amassing huge collections of public record archives in digital form, and how to access those records. Paradoxically, you put stuff in digital form with the idea that you’re going to be able to search it easily, compared with boxes and manual paper. However, it ends up that it’s very difficult to access huge digital collections, especially if they are filled with personally identifiable information (PII) and other forms of sensitive data. What animates me in the papers that I’ve done at IEEE and at other conferences and forums is to talk about the need to apply what we know in the eDiscovery space now with respect to AI. Machine learning technologies can be very helpful to extract out sensitive data from large collections, and to have a public use version of the larger collection in some form in order that people can get access to huge collections of email or other electronic records that constitute public archives.
So I intend to devote a fair amount of time going forward on issues concerning the freedom of information aspects of the law. How do we stay informed about what governments are doing? That’s a difficult question in the US and it’s even more difficult around the world. That is of interest to me. I’m very thankful that I work in a law firm that has allowed me the opportunity to pursue that interest, in addition to thinking about matters that actually result in billable hours! {laughs}
Also, the Information Governance Initiative continues apace with its just published third State of IG Report. (See www.iginitiative.com.) Barclay Blair has led the way on that. I think we are seeing a greater penetration in the corporate space of the idea of IG, that there’s a greater maturity, a greater acceptance of IG councils and IG champions. All of that’s good. We have, as we have had for the last three years, ia Chief Information Governance Officer (CIGO) Summit in Chicago, which will take place on May 9th and 10th. As we always have, we gather together for a single summit 60 or 70 individuals who are card-carrying IG people that have some kind of title in the space. We talk about leadership. And the IGI will continue to be partnering with lots of innovative companies to produce white papers and to have an ongoing conversation about the importance of Information Governance. I’m delighted to be part of that effort.
Thanks, Jason, for participating in the interview!
As always, please share any comments you might have or if you’d like to know more about a particular topic!
Sponsor: This blog is sponsored by CloudNine, which is a data and legal discovery technology company with proven expertise in simplifying and automating the discovery of data for audits, investigations, and litigation. Used by legal and business customers worldwide including more than 50 of the top 250 Am Law firms and many of the world’s leading corporations, CloudNine’s eDiscovery automation software and services help customers gain insight and intelligence on electronic data.
Disclaimer: The views represented herein are exclusively the views of the author, and do not necessarily represent the views held by CloudNine. eDiscovery Daily is made available by CloudNine solely for educational purposes to provide general information about general eDiscovery principles and not to provide specific legal advice applicable to any particular circumstance. eDiscovery Daily should not be used as a substitute for competent legal advice from a lawyer you have retained and who has agreed to represent you.