eDiscovery Daily Blog
Reporting from the EDRM Annual Meeting and a Data Set Update – eDiscovery Trends
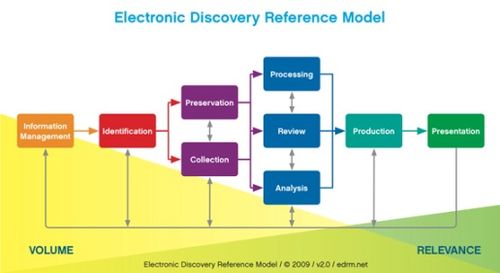
The Electronic Discovery Reference Model (EDRM) Project was created in May 2005 by George Socha of Socha Consulting LLC and Tom Gelbmann of Gelbmann & Associates to address the lack of standards and guidelines in the electronic discovery market. Now, beginning its ninth year of operation with its annual meeting in St. Paul, MN, EDRM is accomplishing more than ever to address those needs. Here are some highlights from the meeting, and an update regarding the (suddenly heavily talked about) EDRM Data Set project.
Annual Meeting
Twice a year, in May and October, eDiscovery professionals who are EDRM members meet to continue the process of working together on various standards projects. This will be my eighth year participating in EDRM at some level and, oddly enough, I’m assisting with PR and promotion (how am I doing so far?). eDiscovery Daily has referenced EDRM and its phases many times in the 2 1/2 years plus history of the blog – this is our 144th post that relates to EDRM!
Some notable observations about today’s meeting:
- New Participants: More than half the attendees at this year’s annual meeting are attending for the first time. EDRM is not just a core group of “die-hards”, it continues to find appeal with eDiscovery professionals throughout the industry.
- Agile Approach: EDRM has adopted an Agile approach to shorten the time to complete and publish deliverables, a change in philosophy that facilitated several notable accomplishments from working groups over the past year including the Model Code of Conduct (MCoC), Information Governance Reference Model (IGRM), Search and Jobs (among others). More on that tomorrow.
- Educational Alliances: For the first time, EDRM has formed some interesting and unique educational alliances. In April, EDRM teamed with the University of Florida Levin College of Law to present a day and a half conference entitled E-Discovery for the Small and Medium Case. And, this June, EDRM will team with Bryan University to provide an in-depth, four-week E-Discovery Software & Applied Skills Summer Immersion Program for Law School Students.
- New Working Group: A new working group to be lead by Eric Mandel of Zelle Hoffman was formed to address standards for working with native files in the different EDRM phases.
Tomorrow, we’ll discuss the highlights for most of the individual working groups. Given the recent amount of discussion about the EDRM Data Set group, we’ll start with that one today!
Data Set
The EDRM Enron Data Set has been around for several years and has been a valuable resource for eDiscovery software demonstration and testing (we covered it here back in January 2011). The data in the EDRM Enron PST Data Set files is sourced from the FERC Enron Investigation release made available by Lockheed Martin Corporation. It was reconstituted as PST files with attachments for the EDRM Data Set Project. So, in essence EDRM took already public domain available data and made the data much more usable. Initially, the data was made available for download on the EDRM site, then subsequently moved to Amazon Web Services (AWS).
In the past several days, there has been much discussion about the personally-identifiable information (“PII”) available within the FERC (and consequently the EDRM Data Set), including social security numbers, credit card numbers, dates of birth, home addresses and phone numbers. Consequently, the EDRM Data Set has been taken down from the AWS site.
The Data Set team led by Michael Lappin of Nuix and Eric Robi of Elluma Discovery has been working on a process (using predictive coding technology) to identify and remove the PII data from the EDRM Data Set. Discussions about this process began months ago, prior to the recent discussions about the PII data contained within the set. The team has completed this iterative process for V1 of the data set (which contains 1,317,158 items), identifying and removing 10,568 items with PII, HIPAA and other sensitive information. This version of the data set will be made available within the EDRM community shortly for peer review testing. The data set team will then repeat the process for the larger V2 version of the data set (2,287,984 items). A timetable for republishing both sets should be available soon and the efforts of the Data Set team on this project should pay dividends in developing and standardizing processes for identifying and eliminating sensitive data that eDiscovery professionals can use in their own data sets.
The team has also implemented a Forensic Files Testing Project site where users can upload their own “modern”, non-copyrighted file samples that are typically encountered during electronic discovery processing to provide a more diverse set of data than is currently available within the Enron data set.
So, what do you think? How has EDRM impacted how you manage eDiscovery? Please share any comments you might have or if you’d like to know more about a particular topic.
Disclaimer: The views represented herein are exclusively the views of the author, and do not necessarily represent the views held by CloudNine Discovery. eDiscoveryDaily is made available by CloudNine Discovery solely for educational purposes to provide general information about general eDiscovery principles and not to provide specific legal advice applicable to any particular circumstance. eDiscoveryDaily should not be used as a substitute for competent legal advice from a lawyer you have retained and who has agreed to represent you.